Core Concepts
Principles
memary integrates itself onto your existing agents with as little developer implementation as possible. We achieve this sticking to a few principles.
-
Auto-generated Memory
- After initializing memary, agent memory automatically updates as the agent interacts. This type of generation allows us to capture all memories to easily display in your dashboard. Additionally, we allow the combination of databases with little or no code!
-
Memory Modules
- Given a current state of the databases, memary tracks users' preferences which are displayed in your dashboard for analysis.
-
System Improvement
- memary mimics how human memory evolves and learns over time. We will provide the rate of your agents improvement in your dashboard.
-
Rewind Memories
- memary takes care of keeping track of all chats so you can rewind agent executions and access the agents memory at a certain period (coming soon).
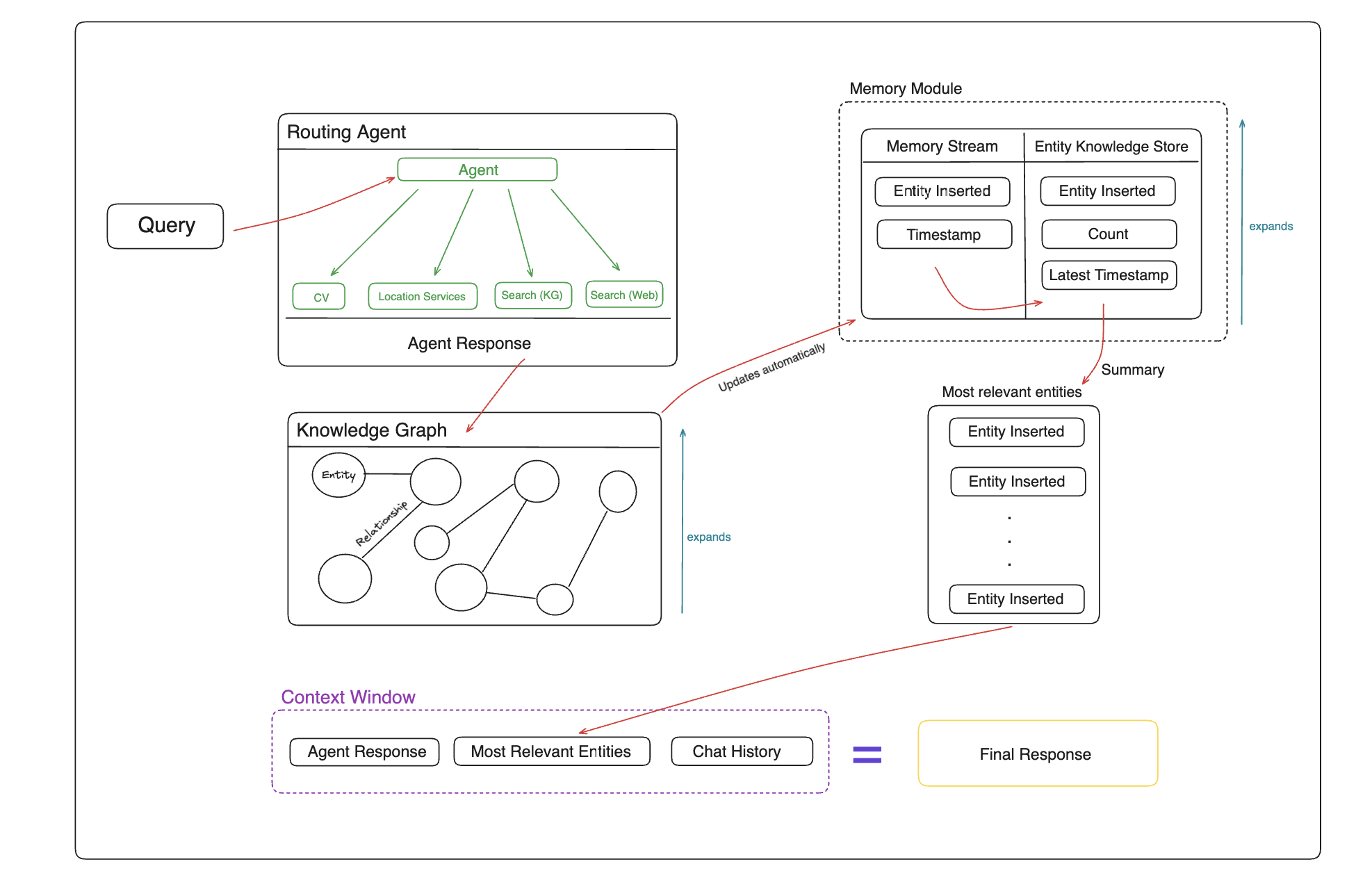
At the time of writing, the above system design includes the routing agent, knoweldge graph and memory modules that are all integrated into the ChatAgent class located in the src/agent directory.
Note
Raw source code for these components can also be found in their respective directories including benchmarks, notebooks, and updates.
Agent
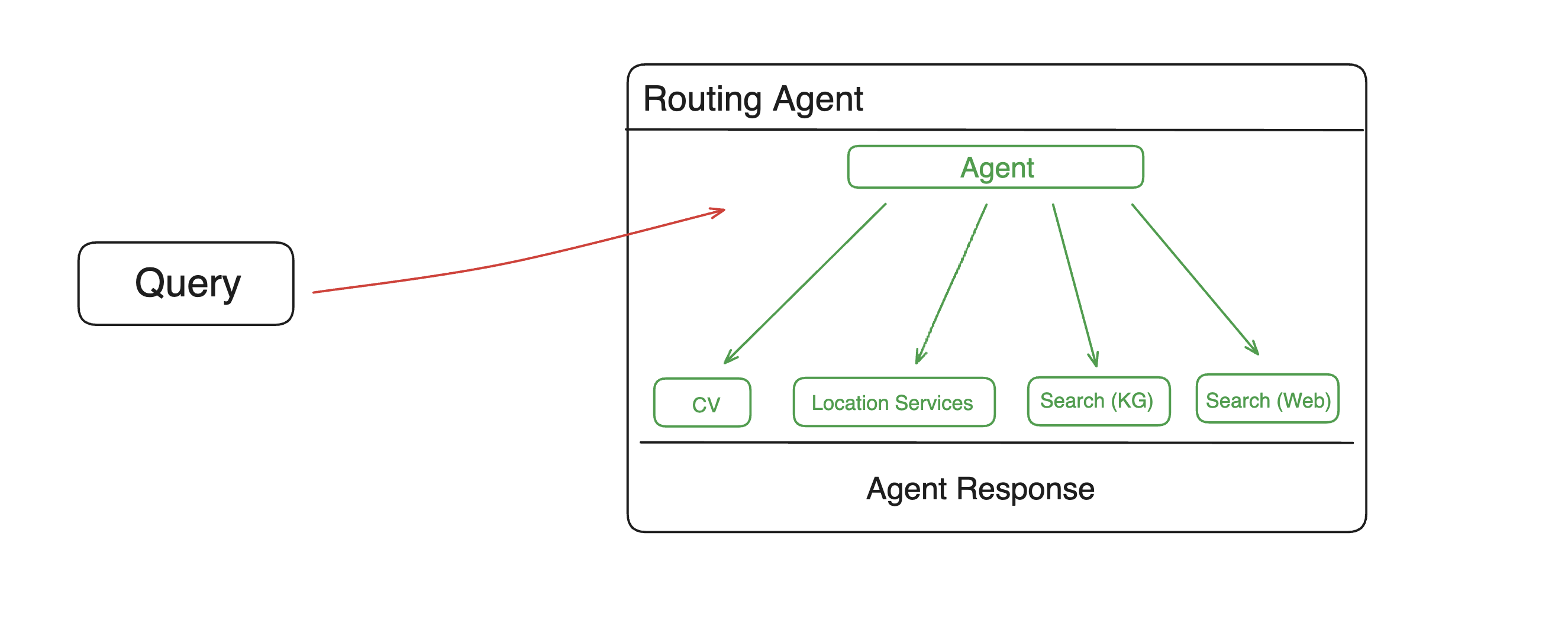
To provide developers, who don't have existing agents, access to memary we setup a simple agent implementation. We use the ReAct agent to plan and execute a query given the tools provided.
While we didn't emphasize equipping the agent with many tools, the search tool is crucial to retrieve information from the knowledge graph. This tool queries the knowledge graph for a response based on existing nodes and executes an external search if no related entities exist. Other default agent tools include computer vision powered by LLaVa and a location tool using geococder and google maps.
Note
In future version releases, the current ReAct agent (that was used for demo purposes) will be removed from the package so that memary can support any type of agents from any provider.
def external_query(self, query: str):
messages_dict = [
{"role": "system", "content": "Be precise and concise."},
{"role": "user", "content": query},
]
messages = [ChatMessage(**msg) for msg in messages_dict]
external_response = self.query_llm.chat(messages)
return str(external_response)
def search(self, query: str) -> str:
response = self.query_engine.query(query)
if response.metadata is None:
return self.external_query(query)
else:
return response
Developers will be able to choose to to intialize memary with the default tools or their own at setup
Purpose in larger system
Each response from the agent is saved in the knowledge graph. You can view responses from various tools as distinct elements that contribute to the user's knowledge.
Future Contributions
- Make your own agent and add as many tools as possible! Each tool expands the agent's ability to answer a wide variety of queries.
- Create an LLM Judge that scores the routing agent and provides feedback.
- Integrate multiprocessing so that the agent can process multiple sub-queries simultaneously. We have open-sourced the query decomposition and reranking code to help with this!
Knowledge Graph
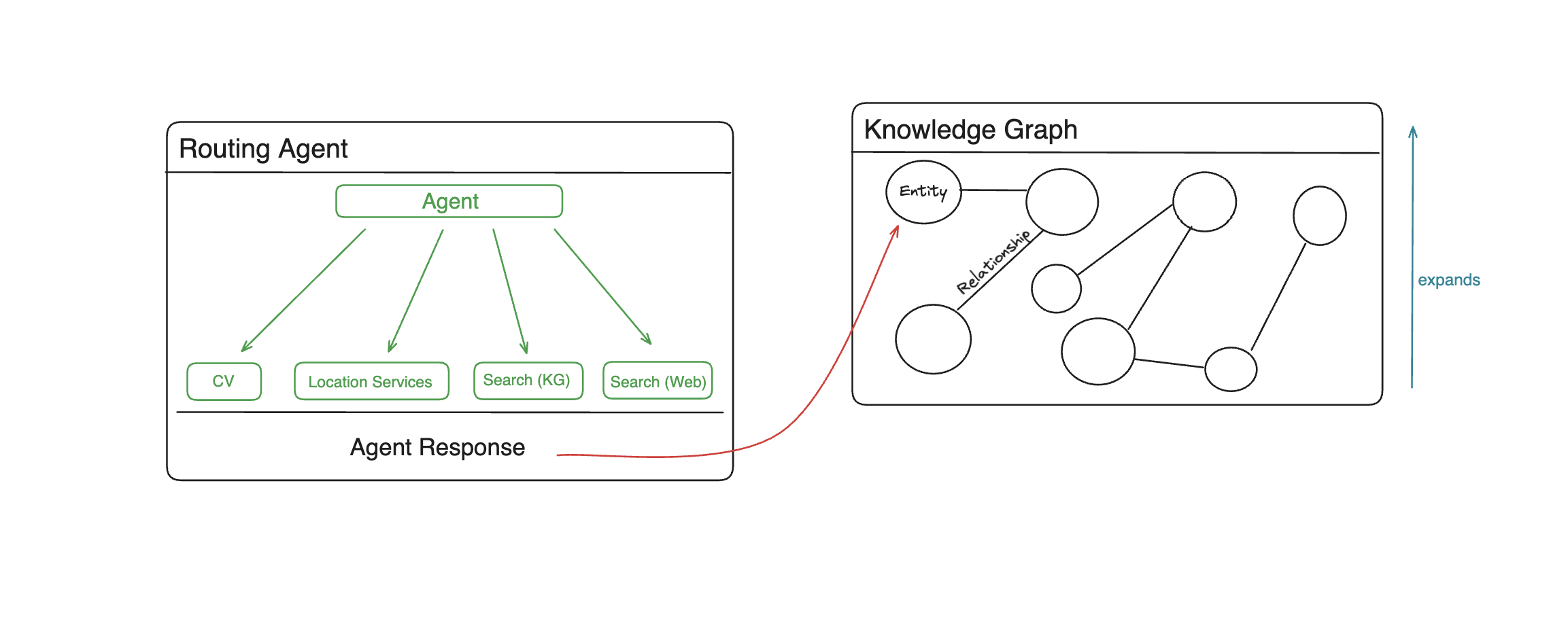
Knowledge Graphs ↔ LLMs
- memary uses a Neo4j graph database to store knoweldge.
- Llama Index was used to add nodes into the graph store based on documents.
- Perplexity (mistral-7b-instruct model) was used for external queries.
Knowledge Graph Use Cases
- Inject the final agent responses into existing KGs.
- memary uses a recursive retrieval approach to search the KG, which involves determining what the key entities are in the query, building a subgraph of those entities with a maximum depth of 2 away, and finally using that subgraph to build up the context.
- When faced with multiple key entities in a query, memary uses multi-hop reasoning to join multiple subgraphs into a larger subgraph to search through.
- These techniques reduce latency compared to searching the entire knowledge graph at once.
def query(self, query: str) -> str:
# get the response from react agent
response = self.routing_agent.chat(query)
self.routing_agent.reset()
# write response to file for KG writeback
with open("data/external_response.txt", "w") as f:
print(response, file=f)
# write back to the KG
self.write_back()
return response
def check_KG(self, query: str) -> bool:
"""Check if the query is in the knowledge graph.
Args:
query (str): query to check in the knowledge graph
Returns:
bool: True if the query is in the knowledge graph, False otherwise
"""
response = self.query_engine.query(query)
if response.metadata is None:
return False
return generate_string(
list(list(response.metadata.values())[0]["kg_rel_map"].keys())
)
Purpose in larger system
Continuously updates the memory modules with each node insertion.
Future Contributions
- Expand the graph’s capabilities to support multiple modalities, i.e., images.
- Graph optimizations to reduce latency of search times.
Memory Modules
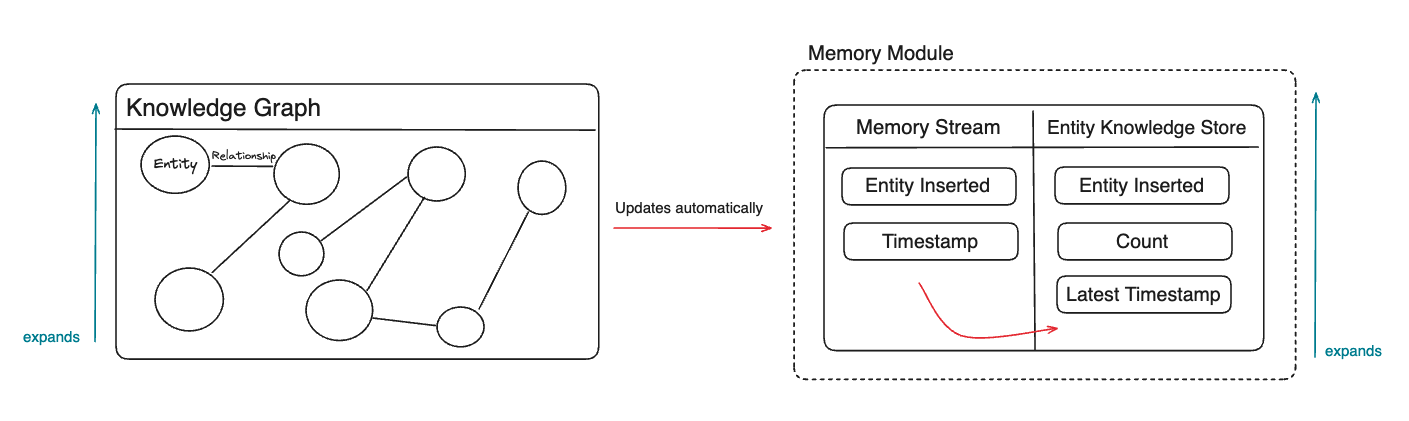
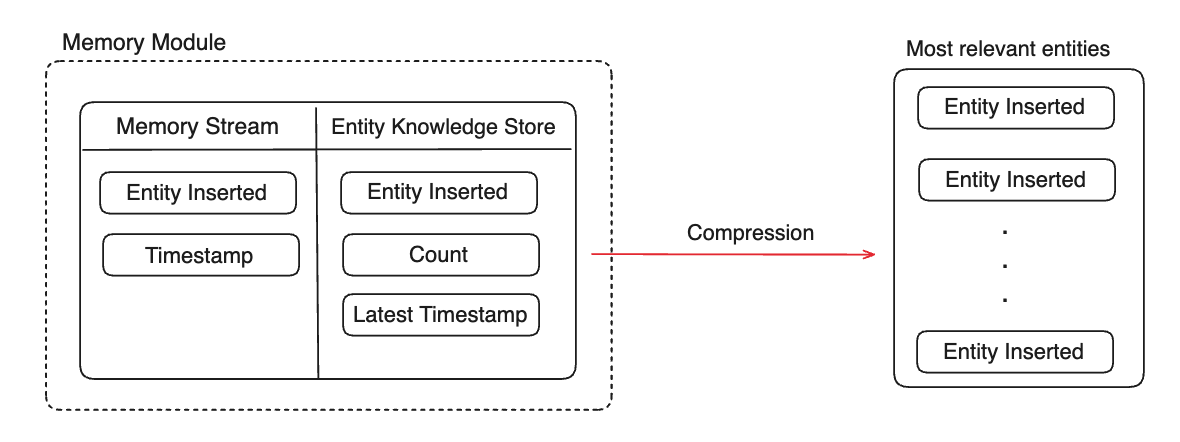
The memory module comprises the Memory Stream and Entity Knowledge Store. The memory module was influenced by the design of K-LaMP proposed by Microsoft Research.
Memory Stream
The Memory Stream captures all entities inserted into the KG and their associated timestamps. This stream reflects the breadth of the users' knowledge, i.e., concepts users have had exposure to but no depth of exposure is inferred. - Timeline Analysis: Map out a timeline of interactions, highlighting moments of high engagement or shifts in topic focus. This helps in understanding the evolution of the user's interests over time.
def add_memory(self, entities):
self.memory.extend([
MemoryItem(str(entity),
datetime.now().replace(microsecond=0))
for entity in entities
])
- Extract Themes: Look for recurring themes or topics within the interactions. This thematic analysis can help anticipate user interests or questions even before they are explicitly stated.
Entity Knowledge Store
The Entity Knowledge Store tracks the frequency and recency of references to each entity stored in the memory stream. This knowledge store reflects users' depth of knowledge, i.e., concepts they are more familiar with than others. - Rank Entities by Relevance: Use both frequency and recency to rank entities. An entity frequently mentioned (high count) and referenced recently is likely of high importance, and the user is well aware of this concept.
def _select_top_entities(self):
entity_knowledge_store = self.message.llm_message['knowledge_entity_store']
entities = [entity.to_dict() for entity in entity_knowledge_store]
entity_counts = [entity['count'] for entity in entities]
top_indexes = np.argsort(entity_counts)[:TOP_ENTITIES]
return [entities[index] for index in top_indexes]
- Categorize Entities: Group entities into categories based on their nature or the context in which they're mentioned (e.g., technical terms, personal interests). This categorization aids in quickly accessing relevant information tailored to the user's inquiries.
def _convert_memory_to_knowledge_memory(
self, memory_stream: list) -> list[KnowledgeMemoryItem]:
"""Converts memory from memory stream to entity knowledge store by grouping entities
Returns:
knowledge_memory (list): list of KnowledgeMemoryItem
"""
knowledge_memory = []
entities = set([item.entity for item in memory_stream])
for entity in entities:
memory_dates = [
item.date for item in memory_stream if item.entity == entity
]
knowledge_memory.append(
KnowledgeMemoryItem(entity, len(memory_dates),
max(memory_dates)))
return knowledge_memory
- Highlight Changes Over Time: Identify any significant changes in the entities' ranking or categorization over time. A shift in the most frequently mentioned entities could indicate a change in the user's interests or knowledge.
- Additional information on the memory module can be found here
Purpose in larger system
- Compress/summarize the top N ranked entities in the entity knowledge store and pass to the LLM’s finite context window alongside the agent's response and chat history for inference.
- Personalize Responses: Use the key categorized entities and themes associated with the user to tailor agent responses more closely to the user's current interests and knowledge level/expertise.
- Anticipate Needs: Leverage trends and shifts identified in the summaries to anticipate users' future questions or needs.
Future Contributions
We currently extract the top N entities from the entitiy knowledge store and pass these entities into the context window for inference. memary can future benefit from more advanced memory compression techniques such as passing only entities that are in the agent's response to the context window. We look forward to related community contributions.
New Context Window

Note
We utilize the the key categorized entities and themes associated with users to tailor agent responses more closely to the user's current interests/preferences and knowledge level/expertise. The new context window is made up of the following:
-
Agent response
retrieve agent responsedef get_routing_agent_response(self, query, return_entity=False): """Get response from the ReAct.""" response = "" if self.debug: # writes ReAct agent steps to separate file and modifies format to be readable in .txt file with open("data/routing_response.txt", "w") as f: orig_stdout = sys.stdout sys.stdout = f response = str(self.query(query)) sys.stdout.flush() sys.stdout = orig_stdout text = "" with open("data/routing_response.txt", "r") as f: text = f.read() plain = ansi_strip(text) with open("data/routing_response.txt", "w") as f: f.write(plain) else: response = str(self.query(query)) if return_entity: # the query above already adds final response to KG so entities will be present in the KG return response, self.get_entity(self.query_engine.retrieve(query)) return response -
Most relevant entities
retrieve important entitiesdef get_entity(self, retrieve) -> list[str]: """retrieve is a list of QueryBundle objects. A retrieved QueryBundle object has a "node" attribute, which has a "metadata" attribute. example for "kg_rel_map": kg_rel_map = { 'Harry': [['DREAMED_OF', 'Unknown relation'], ['FELL_HARD_ON', 'Concrete floor']], 'Potter': [['WORE', 'Round glasses'], ['HAD', 'Dream']] } Args: retrieve (list[NodeWithScore]): list of NodeWithScore objects return: list[str]: list of string entities """ entities = [] kg_rel_map = retrieve[0].node.metadata["kg_rel_map"] for key, items in kg_rel_map.items(): # key is the entity of question entities.append(key) # items is a list of [relationship, entity] entities.extend(item[1] for item in items) if len(entities) > MAX_ENTITIES_FROM_KG: break entities = list(set(entities)) for exceptions in ENTITY_EXCEPTIONS: if exceptions in entities: entities.remove(exceptions) return entities -
Chat history (summarized to avoid token overflow)
summarize chat historydef _summarize_contexts(self, total_tokens: int): """Summarize the contexts. Args: total_tokens (int): total tokens in the response """ messages = self.message.llm_message["messages"] # First two messages are system and user personas if len(messages) > 2 + NONEVICTION_LENGTH: messages = messages[2:-NONEVICTION_LENGTH] del self.message.llm_message["messages"][2:-NONEVICTION_LENGTH] else: messages = messages[2:] del self.message.llm_message["messages"][2:] message_contents = [message.to_dict()["content"] for message in messages] llm_message_chatgpt = { "model": self.model, "messages": [ { "role": "user", "content": "Summarize these previous conversations into 50 words:" + str(message_contents), } ], } response, _ = self._get_gpt_response(llm_message_chatgpt) content = "Summarized past conversation:" + response self._add_contexts_to_llm_message("assistant", content, index=2) logging.info(f"Contexts summarized successfully. \n summary: {response}") logging.info(f"Total tokens after eviction: {total_tokens*EVICTION_RATE}")